BTP / Complex Networks Research Lab, IIT Kharagpur / Prof. Pawan Goyal
LaViDA: Latent Visitation Distribution Alignment for Mathematical Reasoning
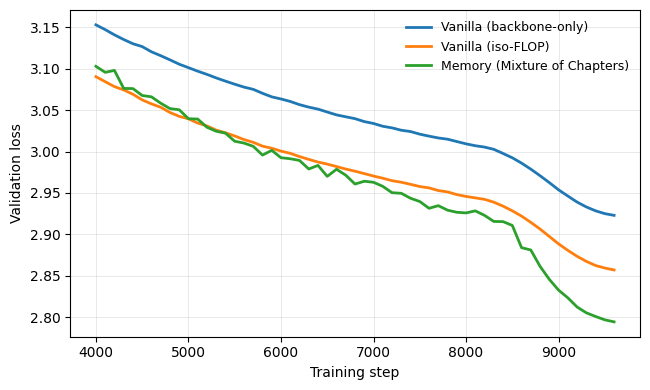
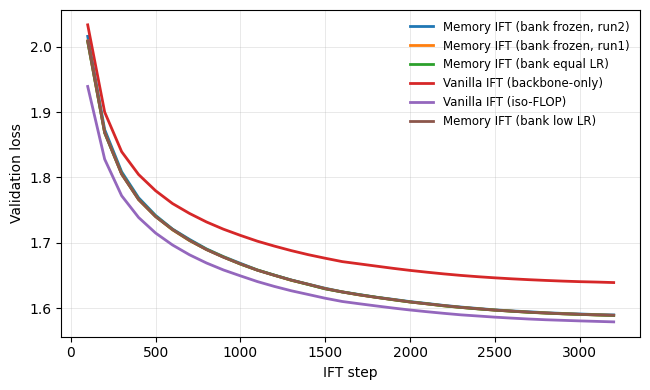
LaViDA asks whether outcome-only GRPO leaves useful reasoning structure on the table. Correct rollouts are projected through a frozen latent encoder, then aligned toward verified expert traces. The current result is deliberately honest: simple nearest-expert alignment is promising under sampling, while the learned chi-square critic is not yet reward-aligned.
- Built Qwen2.5-Math-7B GRPO training with LoRA-r64, vLLM, FlashAttention, and single-H100 rollout scaling.
- Constructed self and Oracle-augmented expert pools: 8,963 self traces plus 3,354 filtered 72B traces embedded on the 7B manifold.
- D_OracleAug ties GRPO on greedy MATH-500 but improves n=8 mean correctness by +4.70pp, p=0.0069.
- On the harder MATH-500 L4-5 subset, the same branch improves n=8 mean correctness by +5.77pp, p=0.0429.
- Chi-square density-ratio matching was null, sharpening my interest in representations that remain useful as models and policies change.
MATH-500 n=8 mean correctness
Seed-0 read: SFT wins greedy; D_OracleAug and SFT are statistically indistinguishable under n=8 sampling.